【Python】numpyでヒストリカル・ボラティリティを計算する
numpy を使ってヒストリカル・ボラティリティを計算するPythonスクリプトを書こうと思います。
※python2で書いてます。
ヒストリカル・ボラティリティとは
過去のデータから算出する変動率のこと。例えば、「日経225は一年で 何% 値動きするかな?」と思ったときに計算できますか?私にはできません。が、そういったことを過去データから表現するのが、ヒストリカル・ボラティリティです。
私にはうまく説明出来ないので他のサイトを読んで下さい(他力本願)。
ヒストリカル・ボラティリティとは|金融経済用語集
計算式の確認
統計学など知りもしない私なので、式の確認をしておきます。
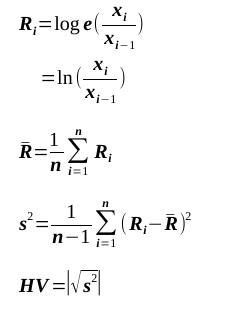
x: 終値
e: 自然対数の底
Ri: 価格変化率の自然対数
R: Ri ~ Ri+nの平均
s2: 不偏分散
HV: ヒストリカル・ボラティリティ(不偏分散の平方根の絶対値)
なるほど分からん。
とにかく、任意期間の価格変化率を自然対数で表現してそれを(不偏)標準偏差する感じかな。なんで自然対数にするかだけど、底が ネイピア数(e) で表現されるから価格の上下が同じパーセントで表せるっぽい。あら不思議。
計算自体はPythonがやってくれるので計算の意味が分からなくても、やることが分かればオッケー。
ってことで次いきます。
ヒストリカル・ボラティリティを計算する
以下の過去記事同様、元データは 汲めども尽きない 無尽蔵さん の過去データ、2015年度の日経225年間データを使用してます。
hv.py
#! /usr/bin/env python # coding: utf-8 import codecs import numpy as np import pandas as pd def rolling_window(a, window): shape = a.shape[:-1] + (a.shape[-1] - window + 1, window) strides = a.strides + (a.strides[-1],) return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides) def hv(closeList=[], n=20, m=240): '''ヒストリカル・ボラティリティを返す [hv]''' dataArr = np.array(closeList) rateArr = np.log(dataArr[1:] / dataArr[0:-1]) stdArr = np.hstack((np.empty(n) * np.nan, np.std(rolling_window(rateArr, n), axis=1, ddof=1))) return (stdArr * np.sqrt(m) * 100).tolist() def main(): with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: [next(f).encode('utf-8') for _ in np.arange(2)] closeList = [float(row.split(',')[4]) for row in f] df = pd.DataFrame(dict(close=closeList, HV=hv(closeList))) print df if __name__ == '__main__': main()
実行結果は以下。見やすいように pandas.DataFrame に落とし込んでいる。
実行結果
HV close 0 NaN 17070.0 1 NaN 16700.0 2 NaN 17140.0 3 NaN 17350.0 4 NaN 16940.0 5 NaN 17040.0 ~省略~ 19 NaN 17550.0 20 20.351678 17500.0 21 18.615100 17640.0 22 16.577364 17640.0 23 16.798516 17900.0 24 15.257340 17640.0 ~省略~ 239 19.398481 18820.0 240 19.279880 18750.0 241 19.385223 18820.0 242 20.350979 19110.0 243 19.991896 19010.0
√240 を掛けて年率換算しています。算出された値が正確かどうかの確認はしていませんが、異常な値はなさそうなので良しとします。
ざっくり解説しようと思います。
def rolling_window(a, window):
shape = a.shape[:-1] + (a.shape[-1] - window + 1, window)
strides = a.strides + (a.strides[-1],)
return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)numpy で pandas の rolling 的な動作をさせるための関数。過去に記事にしたのでそちらも読んでいただけると幸い。
def hv(closeList=[], n=20, m=240):ヒストリカル・ボラティリティを計算するための関数定義。
引数n は何日間の過去データを使って計算するか。
引数m はヒストリカル・ボラティリティを換算するときに掛ける日数。例えば m=240 の場合 √240 が掛けられる。
dataArr = np.array(closeList)引数で受け取った 価格(list) を ndarray型 にして 変数dataArr に代入。
rateArr = np.log(dataArr[1:] / dataArr[0:-1])計算式の確認のところで書いた Ri の計算をしている。
numpy.log() は底が ネイピア数(e) の対数。便利ですね。
stdArr = np.hstack((np.empty(n) * np.nan, np.std(rolling_window(rateArr, n), axis=1, ddof=1)))計算式の確認のところで書いた HV の計算をしている。R や s2 は計算しなくても標準偏差を求める関数 numpy.std() が内部で勝手にやってくれる。
rolling_window() で上記で算出した 変数rateArr(Ri) を n個 ずつ rolling。それらを numpy.std() で標準偏差(axis=1 なので横方向)を算出している。ddof は分散の計算時、分母をいくつ引くか(データ数-ddof)。
numpy.hstack() をしているのは 元データ(closeList) と配列の長さを合わせるために、先頭の欠損部分を numpy.nan で埋めている(好みの問題です)。
return (stdArr * np.sqrt(m) * 100).tolist()√m を掛けて換算、パーセント(×100)にしたものを、ndarray型 から list型 にして返す。
今回の場合は年間営業日数 240 と仮定して、年率換算している。
list型 にしているのは特に意味はない(好みの問題)。
おわりに
ちなみに実行時間は 0.000160930156708 s でした。まぁ遅くはないでしょう。
pythonで書きはしたけど、本当はただヒストリカル・ボラティリティって何かっていうのと、計算式を理解したかっただけ。
間違いとかあったらコメントで指摘してください。
何かの参考になれば幸いです。