【Python】pandasの指数平滑移動平均の値が違った理由
先日 pandas の ewm() を使って指数平滑移動平均(EMA)を計算したが、なんか値ちがくね?となったので調べてみた。
※python2で書いています。
そもそも計算式が違う
とりあえず指数平滑移動平均(EMA)の式の確認をしておきます。
指数平滑移動平均(EMA)の式
EMA(一日目): 単純移動平均(SMA)と同じ
EMA(二日目以降): 前日EMA + α(直近の価格 - 前日EMA)
α: 2.0 / (N日間 + 1.0)
次に pandas の ewm(span=span) の場合。
α: 2.0 / (span + 1.0)
wi = (1 - α)i
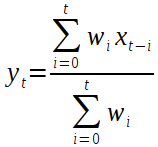
つまり

となっていた。
これは ewm() の adjust 引数の初期値が True になっているからのようです。なので、adjust=False を指定することで指数平滑移動平均(EMA)の式に近づきます。
ewm(span=span, adjust=False) の場合。
y0 = x0
yt = (1 - α)yt-1 + αxt
かなり近いですね。でも、y0 の値が単純移動平均(SMA)ではなく最初の価格を使うようになっています。私は単純移動平均(SMA)を使うことを望む。
ewm() をする前に配列の先頭を変えておけば問題なさそうです。
指数平滑移動平均を計算する
先日書いたスクリプトを編集して、正しいであろう指数平滑移動平均(EMA)を算出したいと思います。
とりあえず、修正したものは以下。ema1 関数がそれ。
sma_ema.py
#! /usr/bin/env python # coding: utf-8 import codecs import pandas as pd def sma(closeList=[], term=5): '''単純移動平均の計算''' return list(pd.Series(closeList).rolling(term).mean()) def ema(closeList=[], term=5): '''指数平滑移動平均の計算''' return list(pd.Series(closeList).ewm(span=term).mean()) def ema1(closeList=[], term=5): '''指数平滑移動平均の計算(修正版)''' s = pd.Series(closeList) sma = s.rolling(term).mean()[:term] return list(pd.concat([sma, s[term:]]).ewm(span=term, adjust=False).mean()) def main(): # 終値の用意 with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: [next(f).encode('utf-8') for _ in range(2)] closeList = [float(row.split(',')[4]) for row in f] # pandas df = pd.DataFrame(dict(close=closeList, sma=sma(closeList), ema=ema(closeList), ema1=ema1(closeList))) print(df) if __name__ == '__main__': main()
ema1 関数の内容は、
sma = s.rolling(term).mean()[:term]単純移動平均(SMA)を計算して、先頭からterm個の要素を 変数sma に代入。今回は term=5 で計算しているので、インデックス的には 0~4 です。
return list(pd.concat([sma, s[term:]]).ewm(span=term, adjust=False).mean())concat() メソッドで先程用意した sma と s[term:] を連結。ewm() メソッドに引数 adjust=False を追加して mean() している。
実行結果は以下。
実行結果
close ema ema1 sma 0 17070.0 17070.000000 NaN NaN 1 16700.0 16848.000000 NaN NaN 2 17140.0 16986.315789 NaN NaN 3 17350.0 17137.384615 NaN NaN 4 16940.0 17061.611374 17040.000000 17040.0 5 17040.0 17053.714286 17040.000000 17034.0 ~省略~ 239 18820.0 18875.635525 18875.635525 18924.0 240 18750.0 18833.757017 18833.757017 18800.0 241 18820.0 18829.171345 18829.171345 18798.0 242 19110.0 18922.780896 18922.780896 18862.0 243 19010.0 18951.853931 18951.853931 18902.0
当たり前だが 0 ~ 3 の値は NaN になっていて、EMAの一日目(4)はSMAと等しくなっている。
ema と ema1 の値が最後の方では収束しているので正しく計算出来ていると判断して良いだろう。例えば、最初のデータはn日後には (1-α)n 倍に(かなり小さく)なるのでデータが一定数あれば計算結果は同じになる。
今回の場合 18 で整数値は等しくなっていた。
おまけ
ema 関数と ema1 関数の実行速度を図ってみた。
how_speed.py
#! /usr/bin/env python # coding: utf-8 import codecs import timeit import pandas as pd def sma(closeList=[], term=5): '''単純移動平均の計算''' return list(pd.Series(closeList).rolling(term).mean()) def ema(closeList=[], term=5): '''指数平滑移動平均の計算''' return list(pd.Series(closeList).ewm(span=term).mean()) def ema1(closeList=[], term=5): '''指数平滑移動平均の計算(修正版)''' s = pd.Series(closeList) sma = s.rolling(term).mean()[:term] return list(pd.concat([sma, s[term:]]).ewm(span=term, adjust=False).mean()) def main(): # 終値の用意 with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: [next(f).encode('utf-8') for _ in range(2)] closeList = [float(row.split(',')[4]) for row in f] loop = 1000 result = timeit.timeit(lambda: ema(closeList), number=loop) print('ema(): {0}'.format(result / loop)) result = timeit.timeit(lambda: ema1(closeList), number=loop) print('ema1(): {0}'.format(result / loop)) if __name__ == '__main__': main()
実行結果
ema(): 0.000745386838913 ema1(): 0.00173953104019
ema1 関数は ema 関数より2.3倍ほど掛かるみたいです。。。
おわりに
ewm(span=span).mean()で指数平滑移動平均と紹介されているのが多い。
「EMA 式」とか検索して出てくる式と違うけど、実際どっちが正しいんでしょうか。直近ではほとんど誤差がなくなるだろうし気にしていないだけなのか。。。
一体どっちなんだ!?