【Python】numpyでヒストリカル・ボラティリティを計算する
numpy を使ってヒストリカル・ボラティリティを計算するPythonスクリプトを書こうと思います。
※python2で書いてます。
ヒストリカル・ボラティリティとは
過去のデータから算出する変動率のこと。例えば、「日経225は一年で 何% 値動きするかな?」と思ったときに計算できますか?私にはできません。が、そういったことを過去データから表現するのが、ヒストリカル・ボラティリティです。
私にはうまく説明出来ないので他のサイトを読んで下さい(他力本願)。
ヒストリカル・ボラティリティとは|金融経済用語集
計算式の確認
統計学など知りもしない私なので、式の確認をしておきます。
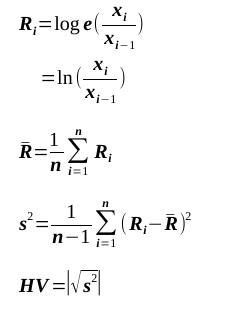
x: 終値
e: 自然対数の底
Ri: 価格変化率の自然対数
R: Ri ~ Ri+nの平均
s2: 不偏分散
HV: ヒストリカル・ボラティリティ(不偏分散の平方根の絶対値)
なるほど分からん。
とにかく、任意期間の価格変化率を自然対数で表現してそれを(不偏)標準偏差する感じかな。なんで自然対数にするかだけど、底が ネイピア数(e) で表現されるから価格の上下が同じパーセントで表せるっぽい。あら不思議。
計算自体はPythonがやってくれるので計算の意味が分からなくても、やることが分かればオッケー。
ってことで次いきます。
ヒストリカル・ボラティリティを計算する
以下の過去記事同様、元データは 汲めども尽きない 無尽蔵さん の過去データ、2015年度の日経225年間データを使用してます。
hv.py
#! /usr/bin/env python # coding: utf-8 import codecs import numpy as np import pandas as pd def rolling_window(a, window): shape = a.shape[:-1] + (a.shape[-1] - window + 1, window) strides = a.strides + (a.strides[-1],) return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides) def hv(closeList=[], n=20, m=240): '''ヒストリカル・ボラティリティを返す [hv]''' dataArr = np.array(closeList) rateArr = np.log(dataArr[1:] / dataArr[0:-1]) stdArr = np.hstack((np.empty(n) * np.nan, np.std(rolling_window(rateArr, n), axis=1, ddof=1))) return (stdArr * np.sqrt(m) * 100).tolist() def main(): with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: [next(f).encode('utf-8') for _ in np.arange(2)] closeList = [float(row.split(',')[4]) for row in f] df = pd.DataFrame(dict(close=closeList, HV=hv(closeList))) print df if __name__ == '__main__': main()
実行結果は以下。見やすいように pandas.DataFrame に落とし込んでいる。
実行結果
HV close 0 NaN 17070.0 1 NaN 16700.0 2 NaN 17140.0 3 NaN 17350.0 4 NaN 16940.0 5 NaN 17040.0 ~省略~ 19 NaN 17550.0 20 20.351678 17500.0 21 18.615100 17640.0 22 16.577364 17640.0 23 16.798516 17900.0 24 15.257340 17640.0 ~省略~ 239 19.398481 18820.0 240 19.279880 18750.0 241 19.385223 18820.0 242 20.350979 19110.0 243 19.991896 19010.0
√240 を掛けて年率換算しています。算出された値が正確かどうかの確認はしていませんが、異常な値はなさそうなので良しとします。
ざっくり解説しようと思います。
def rolling_window(a, window):
shape = a.shape[:-1] + (a.shape[-1] - window + 1, window)
strides = a.strides + (a.strides[-1],)
return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)numpy で pandas の rolling 的な動作をさせるための関数。過去に記事にしたのでそちらも読んでいただけると幸い。
def hv(closeList=[], n=20, m=240):ヒストリカル・ボラティリティを計算するための関数定義。
引数n は何日間の過去データを使って計算するか。
引数m はヒストリカル・ボラティリティを換算するときに掛ける日数。例えば m=240 の場合 √240 が掛けられる。
dataArr = np.array(closeList)引数で受け取った 価格(list) を ndarray型 にして 変数dataArr に代入。
rateArr = np.log(dataArr[1:] / dataArr[0:-1])計算式の確認のところで書いた Ri の計算をしている。
numpy.log() は底が ネイピア数(e) の対数。便利ですね。
stdArr = np.hstack((np.empty(n) * np.nan, np.std(rolling_window(rateArr, n), axis=1, ddof=1)))計算式の確認のところで書いた HV の計算をしている。R や s2 は計算しなくても標準偏差を求める関数 numpy.std() が内部で勝手にやってくれる。
rolling_window() で上記で算出した 変数rateArr(Ri) を n個 ずつ rolling。それらを numpy.std() で標準偏差(axis=1 なので横方向)を算出している。ddof は分散の計算時、分母をいくつ引くか(データ数-ddof)。
numpy.hstack() をしているのは 元データ(closeList) と配列の長さを合わせるために、先頭の欠損部分を numpy.nan で埋めている(好みの問題です)。
return (stdArr * np.sqrt(m) * 100).tolist()√m を掛けて換算、パーセント(×100)にしたものを、ndarray型 から list型 にして返す。
今回の場合は年間営業日数 240 と仮定して、年率換算している。
list型 にしているのは特に意味はない(好みの問題)。
おわりに
ちなみに実行時間は 0.000160930156708 s でした。まぁ遅くはないでしょう。
pythonで書きはしたけど、本当はただヒストリカル・ボラティリティって何かっていうのと、計算式を理解したかっただけ。
間違いとかあったらコメントで指摘してください。
何かの参考になれば幸いです。
【Python】numpyでpandasのrolling的な動作をさせるには
株価データなどをnumpyでいじっているときに pandas の rolling() 的なことをしたいときありませんか?例えば5日間のデータをずらしながら取得したいとか。forループ で良さそうですが遅いのでなしの方向で。
素直に pandas ライブラリを使用すれば解決なんですが、私はひねくれものなので numpy で行いたいのです。
今回はそういった方の参考になるかもしれない記事を書こうと思ってます。
※python2で書いています。
numpyでrolling()的なことをする
私はいい案が浮かばなかったのでググりました。
そしたら こちら が見つかりました。ありがとうございます。
上記のサイトで乗っている以下のコードで良さそうです。勝手に転載してごめんなさい。
def rolling_window(a, window): shape = a.shape[:-1] + (a.shape[-1] - window + 1, window) strides = a.strides + (a.strides[-1],) return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides)
以上で解決です。
おまけ
numpy.lib.stride_tricks.as_strided() が何をしているのかおまけ程度に動かしてみようと思います。
上記のものだけで終わらせる勇気が私にはないので。。。
そもそも numpy.lib.stride_tricks.as_strided() なんて深いところにあったら気付かないよなぁ。とか強がりたいですが、私は numpy の基本的なメソッドすらよく分かっていません。
本題に戻ります。
numpy の公式ドキュメントを見てみましょう。
URL: https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.lib.stride_tricks.as_strided.html#numpy.lib.stride_tricks.as_strided
横文字ですが、いじいじしながら見れば私でも理解できるだろう。
as_strided() の形式(定義)は以下。
as_strided(x, shape=None, strides=None, subok=False, writeable=True)
引数の意味
- x: 元になるndarray型の配列
- shape: 新しい配列(view)の形状
- strides: 新しい配列(view)の縦・横方向の進み具合
- subok: サブクラスを保持するか
- writeable: 書き込み可能にするか
今回は subok と writeable はどうでもいいですね、シカトします。
また、上記だけではピンとこないので少し触ってみます。
以下、間違ったコードを書きます。
as_strided.py
#! /usr/bin/env python # coding: utf-8 import numpy as np from numpy.lib.stride_tricks import as_strided xArr = np.arange(25, dtype='uint16') print(xArr) print(as_strided(xArr, shape=(5, 5))) print(as_strided(xArr, shape=(5, 5), strides=(1, 1)))
np.arange() で 0~24 の配列(ndarray)を 変数xArr に用意(代入)しています。各要素の型は usigned int16 している。
はじめに、用意した配列(xArr)を出力。次に as_strided() に x と shape を指定して出力(5×5で出力する想定)。次に x, shape, strides を指定して出力(縦横1要素ずつ進める想定)。
実行結果
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19] [20 21 22 23 24]] [[ 0 256 1 512 2] [ 256 1 512 2 768] [ 1 512 2 768 3] [ 512 2 768 3 1024] [ 2 768 3 1024 4]]
最初の出力は問題なし。
2つめの出力は shape=(5, 5) と指定しているので 5×5 の配列になっています。予想通りの出力ですね。
3つめの出力は、、、256 とか 512 とか どこから来たんだよって数が出力されています。
これは strides の値が間違っているからです。strides が受け取る値は縦横で進むバイト数を指定しないといけません。今回は unsigned int16 にしているので、配列(xArr)内の要素は1つあたり 16bit で格納されています。つまり 2byte なので strides=(2, 2) としてあげなければいけなかったのです。
以下、修正したコード。
as_strided.py
#! /usr/bin/env python # coding: utf-8 import numpy as np from numpy.lib.stride_tricks import as_strided xArr = np.arange(25, dtype='uint16') print(xArr) print(as_strided(xArr, shape=(5, 5))) print(as_strided(xArr, shape=(5, 5), strides=(2, 2)))
strides=(2, 2) に変更しただけ。
実行結果
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14] [15 16 17 18 19] [20 21 22 23 24]] [[0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8]]
先程のわけの分からない数字はなくなり、縦・横ともに1要素ずつ進んだ値になっているのが確認できるかと思います。
ちなみに、要素を2つずつ進めたい場合は 2byte × 2 なので strides=(4, 4) とすればいいです。また、今回は 2byte でしたが、ndarray の生成時に dtype を指定しなかった場合は大体自動で int64 か float64 になると思うので、要素1つあたり 64bit → 8byte です。
なんとなく分かったでしょうか?
日本語が不自由なんで分かりにくいでしょうが、色々動かしてみると分かると思います。
おわりに
株価データの分析の話だけど、n日間の最大値・最小値とかを計算したいときに使うと便利ですね。
何かの参考になれば幸いです。
【Python】numpyで指数平滑移動平均を計算する
前回 pandas を使って指数平滑移動平均(EMA)を修正しつつ計算したが、実行が遅い(?)ので numpy で高速化できないかと思ってスクリプトを書いてみた。
前回の内容は以下。
指数平滑移動平均を計算する
とりあえず今回作ったスクリプトを載せておく。いつも通りpython2で書いてます。
ちなみに前回と同様でデータは 2015年度の日経225 を使用してます。
numpy_ema.py
#! /usr/bin/env python # coding: utf-8 import codecs import numpy as np import pandas as pd def np_ema(closeList=[], term=5): '''numpyで指数平滑移動平均の計算''' dataArr = np.array([sum(closeList[0: term]) / term] + closeList[term:]) alpha = 2 / (term + 1.) wtArr = (1 - alpha)**np.arange(len(dataArr)) xArr = (dataArr[1:] * alpha * wtArr[-2::-1]).cumsum() / wtArr[-2::-1] emaArr = dataArr[0] * wtArr + np.hstack((0, xArr)) return np.hstack((np.empty(term - 1) * np.nan, emaArr)).tolist() def main(): with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: # header = [next(f).encode('utf-8') for _ in np.arange(2)] [next(f).encode('utf-8') for _ in np.arange(2)] closeList = [float(row.split(',')[4]) for row in f] df = pd.DataFrame(dict(close=closeList, np_ema=np_ema(closeList))) print df if __name__ == '__main__': main()
実行結果を見やすくするために pandas を使っています。
以下、実行結果。
実行結果
close np_ema 0 17070.0 NaN 1 16700.0 NaN 2 17140.0 NaN 3 17350.0 NaN 4 16940.0 17040.000000 5 17040.0 17040.000000 ~省略~ 239 18820.0 18875.635525 240 18750.0 18833.757017 241 18820.0 18829.171345 242 19110.0 18922.780896 243 19010.0 18951.853931
問題なく計算できてますよね(?)
np_ema() 関数の解説をざっくりしたいと思います。
np_ema() 関数は引数に、終値のリスト(closeList) と 平均する期間(term)を取ります。
dataArr = np.array([sum(closeList[0: term]) / term] + closeList[term:])受け取った closeList の先頭(term期間)を平均値にして、それ以降の終値を連結したものを ndarray型 にして 変数dataArr に代入。
alpha = 2 / (term + 1.)平滑定数αの公式に則って、算出結果を 変数alpha に代入。小数点以下が出る可能性があるので float型 になるようにピリオドをつけている。
wtArr = (1 - alpha)**np.arange(len(dataArr))
xArr = (dataArr[1:] * alpha * wtArr[-2::-1]).cumsum() / wtArr[-2::-1]
emaArr = dataArr[0] * wtArr + np.hstack((0, xArr))numpy を使用して forループ を使うとかえって遅くなる(と思う)。少なくともpythonの ループ処理は低速だ。そのため forループ を回避するために、指数平滑移動平均(EMA)の計算式を展開して計算することにした。
指数平滑移動平均の計算式は以下ですよね。
y0 = 単純移動平均(SMA0)
yt = (1 - α)yt-1 + αxt
展開して整理した数式は以下。

法則性があるのが分かりますね。ちなみに今回は
y0 = x0 = SMA0
ですね。また、
y0 = x0(1 - α)0 + 0
とすればいい感じに計算できそうです。
以上を踏まえてpythonのコードに戻ります。
wtArr = (1 - alpha)**np.arange(len(dataArr))x0(1 - α)t の (1 - α)t の部分を 変数wtArr に代入しています。
xArr = (dataArr[1:] * alpha * wtArr[-2::-1]).cumsum() / wtArr[-2::-1]変数wtArr を流用しているので少し分かりにくいが α[x1(1-α)t-1+x2(1-α)t-2+...+xt-2(1-α)1+xt-1(1-α)0] の部分(t>0)を 変数xArr に代入している。
wtArr[-2::-1] を cumsum() したものを wtArr[-2::-1] で割ると(1-α)が約分されるので階上的な部分が一行で再現できる。
emaArr = dataArr[0] * wtArr + np.hstack((0, xArr))上記で用意したものを使って指数平滑移動平均を計算して 変数emaArr に代入。np.hstack((0, xArr)) にしているのは先程用意した 変数xArr の式では t=0 の場合(xArr[0]=0)を再現できなかったので、この段階で 0 を先頭に追加した。
return np.hstack((np.empty(term - 1) * np.nan, emaArr)).tolist()関数の戻り値。リストの長さが元の終値のリストと異なると気持ち悪いので、最初の単純移動平均の計算時に消失した部分に Nan を追加している。ndarray のままでもいいがなんとなく tolist() でpythonの list型 に直して返すようにした。
以上で、解説終わり。
実行速度
で、実行時間はどうなったのか確認したいと思います。
前回 pandas で指数平滑移動平均を計算した関数と比較したいと思います。
how_speed.py
#! /usr/bin/env python # coding: utf-8 import codecs import timeit import numpy as np import pandas as pd def ema(closeList=[], term=5): '''指数平滑移動平均の計算''' return list(pd.Series(closeList).ewm(span=term).mean()) def ema1(closeList=[], term=5): '''指数平滑移動平均の計算(修正版)''' s = pd.Series(closeList) sma = s.rolling(term).mean()[:term] return list(pd.concat([sma, s[term:]]).ewm(span=term, adjust=False).mean()) def np_ema(closeList=[], term=5): '''numpyで指数平滑移動平均の計算''' dataArr = np.array([sum(closeList[0: term]) / term] + closeList[term:]) alpha = 2 / (term + 1.) wtArr = (1 - alpha)**np.arange(len(dataArr)) xArr = (dataArr[1:] * alpha * wtArr[-2::-1]).cumsum() / wtArr[-2::-1] emaArr = dataArr[0] * wtArr + np.hstack((0, xArr)) return np.hstack((np.empty(term - 1) * np.nan, emaArr)).tolist() def main(): # 終値の用意 with codecs.open('./nikkei_225.csv', 'r', encoding='utf-8') as f: [next(f).encode('utf-8') for _ in range(2)] closeList = [float(row.split(',')[4]) for row in f] loop = 1000 result = timeit.timeit(lambda: np_ema(closeList), number=loop) print('np_ema(): {0}'.format(result / loop)) result = timeit.timeit(lambda: ema(closeList), number=loop) print('ema(): {0}'.format(result / loop)) result = timeit.timeit(lambda: ema1(closeList), number=loop) print('ema1(): {0}'.format(result / loop)) if __name__ == '__main__': main()
実行結果
np_ema(): 0.000101397037506 ema(): 0.000755774974823 ema1(): 0.00177794122696
前回の ema関数 より7.45倍、ema1関数 より17.53倍ほど高速化されたみたいです。多分メモリは結構食ってると思います。
おわりに
こんな面倒くさいことをしなくても numba ライブラリというものを使えば forループ が高速になるみたいですね。私は @jit なんぞそれって感じです。
何かの参考になれば幸いです。