【Python】ランダムウォークを再現してみる
先日ランダムウォーク(ブラウン運動)について調べたので、今回はPythonを使って(単純)ランダムウォークを再現してみようと思う。
※python2で書いてます。
計算式の確認
・ランダム
![[X_n]_{ n = 0 }^{ infinity } = [x_0, x_1, x_2, ..., x_{ infinity - 1 }, x_infinity]](https://cdn-ak.f.st-hatena.com/images/fotolife/t/turtlechan/20190917/20190917230524.png)
規則性のない数字の羅列。
・(単純)ランダムウォーク
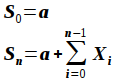
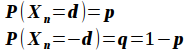
ランダムをその都度加えていったものがランダムウォーク。ちなみに、ある値d が + か - の二択の場合は単純ランダムウォークでしたね。
ランダムウォークを再現する
ここからPythonを使って(単純)ランダムウォークをしてみたいと思います。
配列を使うので numpy とグラフ化が楽なので pandas を使います。
処理の流れは
ランダムの配列作成 → スタート地点(a)を決めて順に足し算
で良いでしょう。
ランダム と (単純)ランダムウォーク の違いを視覚的に確認・比較したい(私が)ので見出しを分けます。
ランダム
単純ランダムウォークにする前提なので -1 か +1 の二択の配列を作成して表示したいと思います。
とりあえず250個生成してます。また、値が一定になるように今回は seed(0) にしています。実行ごとで異なるとランダムウォークと比較できないので。
rnd.py
#! /usr/bin/env python # coding: utf-8 import numpy as np import pandas as pd import matplotlib.pyplot as plt def rnd(): np.random.seed(0) return np.random.choice((-1, 1), 250) if __name__ == '__main__': s = pd.Series(rnd()) plt.show(s.plot(ylim=(-2, 2)))
実行結果
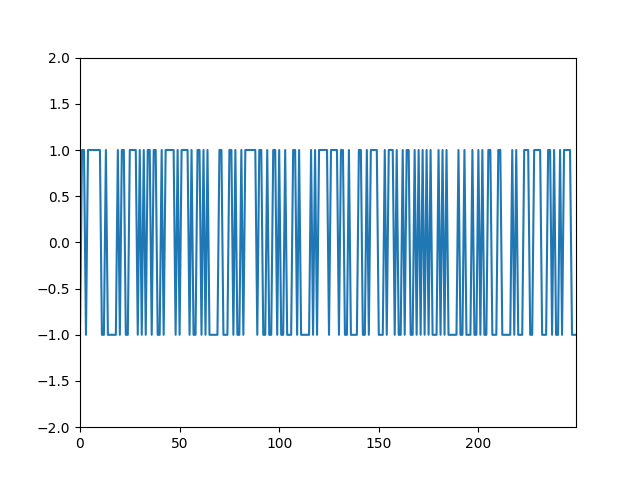
折れ線グラフなので分かりにくいかもしれませんが、y軸が不規則に -1 か +1 で変動しています。
(単純)ランダムウォーク
上記で作成したランダムな配列を np.cumsum() で足していけば良さそうです。
別ファイルを作って先程のスクリプトをインポートして利用する形で作ります。
rnd_walk.py
#! /usr/bin/env python # coding: utf-8 import numpy as np import pandas as pd import matplotlib.pyplot as plt import rnd if __name__ == '__main__': a = 0 rndArr = np.hstack((a, np.cumsum(rnd.rnd()) + a)) s = pd.Series(rndArr) plt.show(s.plot())
実行結果
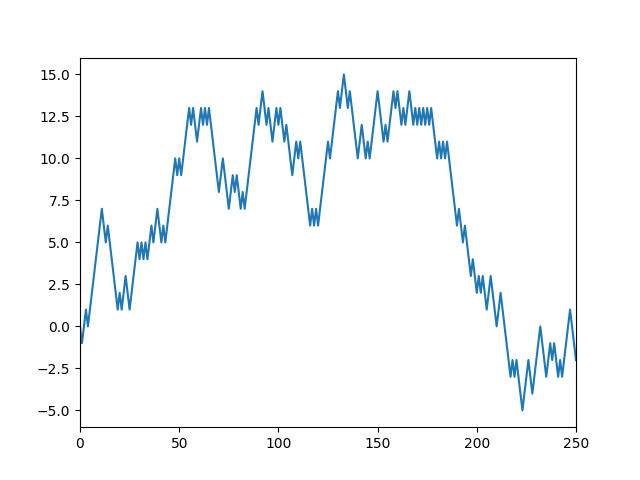
単純ランダムウォークのグラフが表示できたかと思います。ちなみに今回スタート地点(a)は 0 にしました。
おまけ
単純ランダムウォークをグラフ化してみましたが、株価の推移に似ていますよね。
この後の動き予測できますか?
-1 と +1 の確率がそれぞれ 1/2 でプラスに偏りすぎているので、下がると思いますか?
それとも、-5 で底を付いたので上昇トレンドでしょうか?
多分どちらも正しいのでしょう。ただし結果を見ればどちらかが間違っていることでしょう。不思議ですね。
答え
上昇してますね。。。
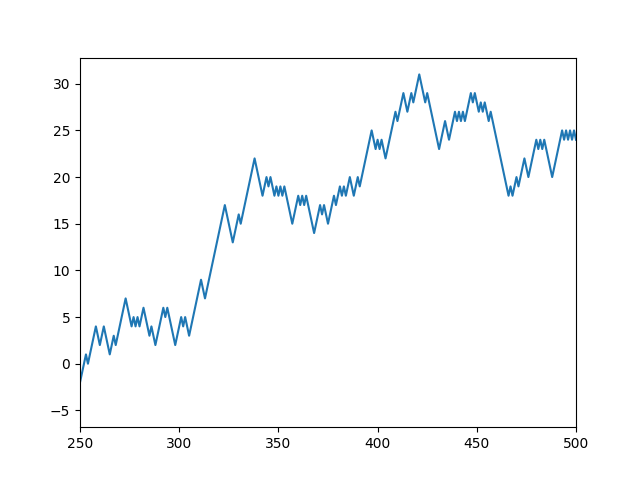
seed の値を 0 にしたままランダムを250個から500個に拡張してランダムウォークにした。そして 250 ~ 500 までをグラフ化したものです。
ランダムなものを予測すること自体間違ってる?
ランダムは予測できないからランダムな訳で、予測できたらランダムではなくなります。そう考えれば、ランダムを予測するのは間違ったことでしょう。
けれど、人って無意識に予測しようとしますし、予測を立ててからでないと行動に移すのが難しいですよね。
株やFXではなおさらです。
おわりに
今回グラフを見て、-1 と +1 の確率が等しくてもかなり偏りが出ることが分かりました。確率は大数でないとあまり意味がないのは知っていましたが。。。
あと、話がそれるけど基本的に「勝ち」か「負け」のゲームでは手数料があるし、投資関係で言えば利益が出れば税金が掛かる。
何が言いたいかというと例えば 負けが -1 だとすれば 勝ちは +0.8 とかアンフェアなゲームじゃないですか。。。正規分布で言うと頂点がマイナス側にあるんですよ。恐ろしい。
何かの参考になれば幸いです。